
yyrcd
2022
Aug 01
%%{init: {'theme': 'base', 'themeVariables': { 'fontSize': '30px', 'fontFamily': 'times'}}}%%
graph TD
A(x) -- Neural Network --> B(u)
B -- "autograd.grad()" --> C(u__x)
C -- "autograd.grad()" --> D(u__x__x)
B .-> E(loss)
C .-> E(loss)
D .-> E(loss)
E --> F{{loss.backward}}%%{init: {'theme': 'base', 'themeVariables': { 'fontSize': '40px', 'fontFamily': 'times'}}}%%
graph LR
subgraph "2nd order derivative"
C(u__x) --- Ss(scale) --> D(scaled u__x) -- "autograd.grad()" ---> E(scaled u__x__x) --- Su(unscale) --> F(u__x__x)
Scaler(deriv_scaler) -.- Ss
Scaler -.- Su
style Ss fill:#f4ddff
style Su fill:#f4ddff
style Scaler fill:#76b900
end
E --> G{{INFs/NaNs<br/> detected?}} -- "Yes" --> H{{Skip this iteration,<br/> update deriv_scaler}}
G -- "No" --> K{{Continue}}
%% G -- "No" --> I{{loss.backward}}2022
Apr 07
排列组合
隔板法
n 个球,k 个桶,有多少种分法?
相当于有 k - 1 个板子,一共有 n + k - 1 个物体,在这么多物体里放入 k - 1 个板子,剩下全部放球,因此是 C(n+k-1, k-1),其中 C(n, r) = n! / (n-r)! r!
Ref: 巧用隔板法解答组合数学问题 - 橘子网
2021
2021
Dec 31
Nsight analysis
nsys nvprof python benchmark.py
nv-nsight-cu-cli --launch-skip 1 --launch-count 3 python benchmark.py
nv-nsight-cu-cli --kernel-regex "cuAngularAEVs" --launch-skip 1 --launch-count 1 python benchmark.py
ncu -f -o my_report_%h_%i --set=detailed --section=SourceCounters --import-source=yes --launch-skip=1 --launch-count=3 python benchmark.pymemory efficency: cuda-training-series/exercises/hw8 at master · olcf/cuda-training-series
nv-nsight-cu-cli --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum,l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum,l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_ld.ratio,l1tex__t_sectors_pipe_lsu_mem_global_op_st.sum,l1tex__t_requests_pipe_lsu_mem_global_op_st.sum,l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_st.ratio,smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct,smsp__sass_average_data_bytes_per_sector_mem_global_op_st.pct --launch-count 3 ./a.outRef:
2021
Sep 16
Register 读写只需要半个 cycle,先写再读
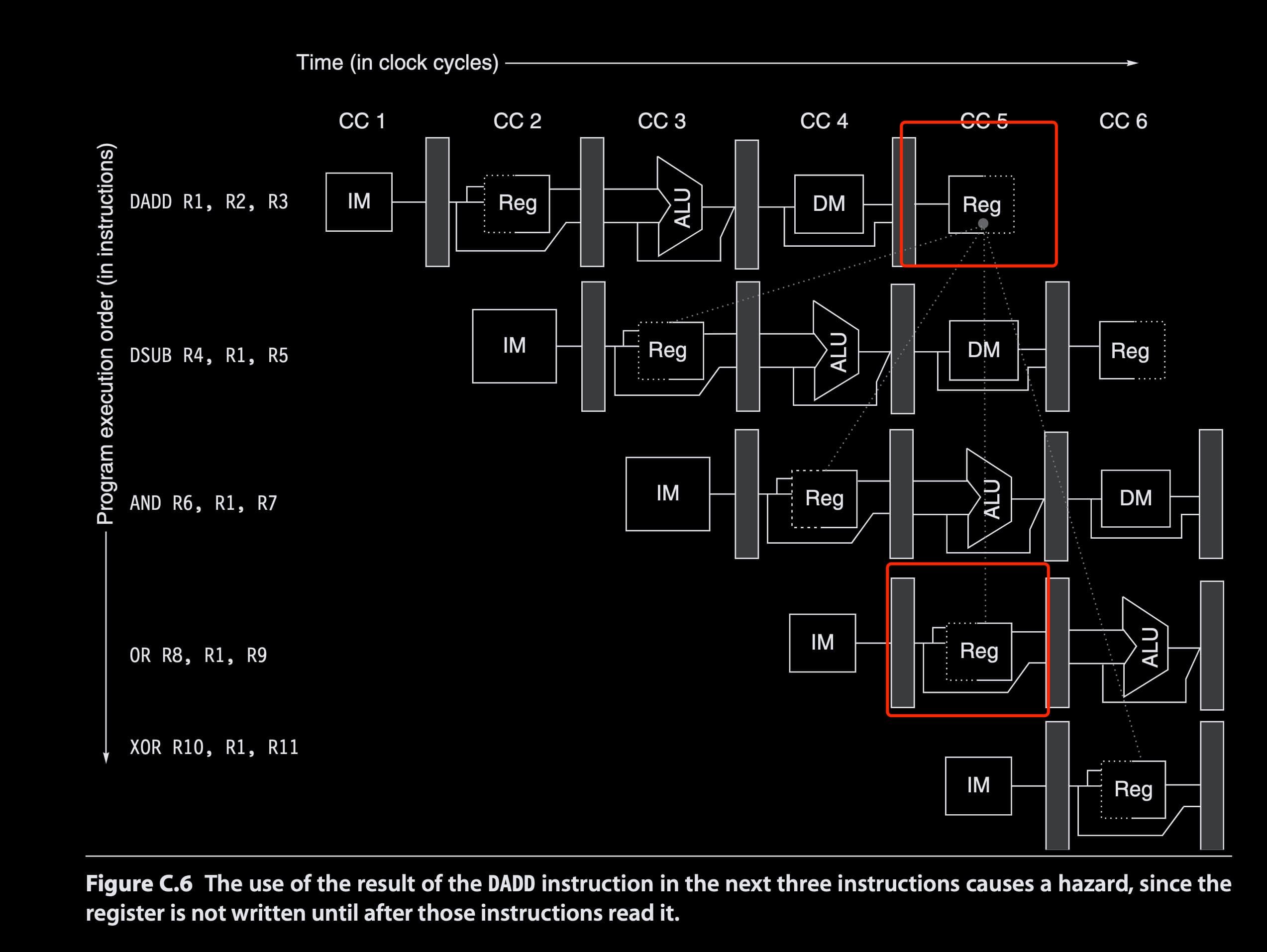
The OR instruction also operates without incurring a hazard because we perform the register file reads in the second half of the cycle and the writes in the first half
每个 cycle 都是先写再读的,那个实线和虚线的意思是,ID (Instruction Decode) 阶段用到的是读,发生在后半个 cycle(实线),WB (Write Back) 阶段需要写入 Register,发生在前半个 cycle(实线)。 因此图中的 OR Instruction 没有 data harzard。
2021
Sep 02
Bash argument
For example submit.sh
POSITIONAL=()
while [[ $# -gt 0 ]]; do
key="$1"
case $key in
-c|--config)
CONFIG="$2"
shift # past argument
shift # past value
;;
-n|--notes)
NOTES="$2"
shift # past argument
shift # past value
;;
-m|--mode)
MODE="$2"
shift # past argument
shift # past value
;;
*) # unknown option
POSITIONAL+=("$1") # save it in an array for later
shift # past argument
;;
esac
done
set -- "${POSITIONAL[@]}" # restore positional parameters
# set default value
if [ -z ${MODE+x} ]; then echo "MODE is unset, set to default as test"; MODE=test; fi
if [ -z ${NOTES+x} ]; then echo "NOTES is unset, set to default as none"; NOTES=ani; fi
echo
if [ -z "${CONFIG-}" ]; then
# unset
echo "Must provide a config file"
exit 1
else
# set
echo "CONFIG = ${CONFIG}"
echo "MODE = ${MODE}"
echo "NOTES = ${NOTES}"
echo
fiUsage:
bash submit.sh -c config.yaml -n "I am a note" -m runoutput
CONFIG = config.yaml
MODE = run
NOTES = I am a note2021
Sep 02
X86/X64
byte (charactor): 8 bits R8b
word: 8 * 2 bits (16) R8w
double word: 8 * 4 bits (32) R8d
quad word: 8 * 8 bits (64) R8
note:
- Rax, Rbx ..... R8 is for X64 (64-bit instruction)
- X86 have Eax, Ebx .... (32-bit instruction). For X64, the lower 32 bits of
Rax, Rbx...areEax, Ebx...
MIPS
byte (charactor): 8 bits half word: 8 * 2 bits (16) word: 8 * 4 bits (32) double word: 8 * 8 bits (64)
2021
Aug 24
快捷键 | Shortcuts
iTerm
Cmd + Option + leftNavigate split panes
VS Code
Cmd + PQuick File NavigationCmd + B隐藏/打开 侧边栏Ctrl + Up代码向上移动一行Cmd + Shift + .上方的 Navigation Bar (Breadcrumbs) (有 dropdown)Cmd + Shift + ;上方的 Navigation Bar (Breadcrumbs) (无 dropdown)
Terminal
Ctrl + W删除上一个单词Ctrl + U可以删除光标之前的内容Ctrl + K可以删除光标之后的内容
Mac
Option + ↑: Show all windowsCtrl + Cmd + X: Open folder in TerminalOption + Cmd + H: Hide all
Chrome
Crtl + Shift + Del: Delete current suggestion from 地址栏
2021
Aug 18
2021
Aug 15
健康饮食 | 血糖生成指数
标准:
- 高GI:GI>70,食物进入胃肠后能被迅速消化,葡萄糖进入血液后峰值高,血糖迅速升高
- 中GI:55≤GI≤70
- 低GI:GI<55,食物在胃肠中停留时间较长,葡萄糖进入血液后的峰值低血糖升高的速度慢。
Todo:
- 蒸土豆 可当主食
- 蒸胡萝卜
- 蒸拌茄子
- 全麦面包
简表:
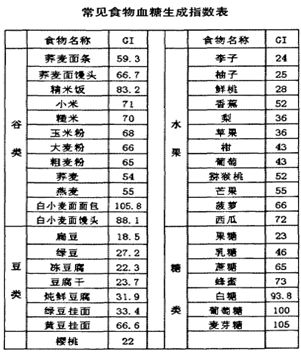
全表:
{kind=link}
Ref:
2021
Aug 14
Dockerfile Command
- FROM: https://docs.docker.com/engine/reference/builder/#from
- 可以使用多个From image as name,多阶段构建
- 使用 COPY 而不是 ADD: https://docs.docker.com/engine/reference/builder/#copy
- COPY dest assume 的相对链接是在 workdir
- RUN vs CMD
2021
Aug 05
2021
Jul 28
Redirect Output to File
redirect stdout
command > fileredirect stderr
command 2> fileredirect stdout and stderr to different files
command > file.out 2> file.errredirect stdout and stderr to the same file
command > file 2>&12021
Jul 15
find
count lines recursively
find . -name '*.py' | xargs wc -lFind all the xyz files in dir1, copy the corresponding png files in dir2 to dir1.
richard@mordor~/test> tree
.
├── dir1
│ ├── 1.xyz
│ ├── 2.xyz
│ └── 3.xyz
└── dir2
├── 1.png
├── 2.png
└── 3.png
2 directories, 6 files
richard@mordor~/test> find ./dir1 -type f -name '*.xyz' -exec bash -c 'file="$1"; filename="$(basename ${file} .xyz)"; command="cp dir2/${filename}.png dir1/"; echo "${command}"; bash -c "${command}"' bash {} \;
cp dir2/3.png dir1/
cp dir2/2.png dir1/
cp dir2/1.png dir1/
richard@mordor~/test> tree
.
├── dir1
│ ├── 1.png
│ ├── 1.xyz
│ ├── 2.png
│ ├── 2.xyz
│ ├── 3.png
│ └── 3.xyz
└── dir2
├── 1.png
├── 2.png
└── 3.png
2 directories, 9 files2021
Jul 14
内存 pageout swapout
$ vm_stat 2
Mach Virtual Memory Statistics: (page size of 16384 bytes)
free active specul inactive throttle wired prgable faults copy 0fill reactive purged file-backed anonymous cmprssed cmprssor dcomprs comprs pageins pageout swapins swapouts
56511 383075 10917 371732 0 111455 2131 68649803 5590148 38464146 1059943 257199 362954 402770 175812 75492 298067 705884 1240072 10900 0 0
57043 383207 10916 371045 0 111480 2136 5898 357 3281 0 0 362953 402215 175811 75492 1 0 0 0 0 0
59374 381386 10916 370487 0 111530 2128 2259 119 1407 0 152 362953 399836 175811 75492 0 0 0 0 0 0
59436 381385 10917 370461 0 111491 2129 3927 238 2242 0 0 362954 399809 175811 75492 0 0 0 0 0 0
58088 383078 10927 370769 0 110906 2106 5078 238 2648 0 0 362965 401809 175809 75492 2 0 0 0 0 0
56127 383643 10993 371406 0 111726 2127 8707 119 3541 7 0 363066 402976 174009 75375 1751 0 64 0 0 0
55010 384327 11000 372120 0 111361 2140 6645 357 3852 0 0 363116 404331 173978 75363 30 0 41 0 0 0
57239 382808 11014 371050 0 111818 2178 6626 259 3642 0 0 363160 401712 173880 75363 98 0 17 0 0 02021
Jul 13
M1 Cinebench 性能跑分
| Cinebench R23 单核 | Cinebench R23 多核 | |
|---|---|---|
| 2020 Mac mini (Apple Sillicon, M1, 16G RAM) | 1488 | 7583 |
| 2017 13" Macbook Pro (Intel, 2.3GHz dual-core i5, 16G RAM) | 860 | 2215 |
| Hackintosh (Intel, 3.41GHz dual-Core Core i5, 24G RAM) | 894 | 3104 |
2021
Jul 11
Rectangular extra centering command
Add an extra centering command with custom size (ctrl + option + N)
defaults write com.knollsoft.Rectangle specified -dict-add keyCode -float 45 modifierFlags -float 786721
defaults write com.knollsoft.Rectangle specifiedHeight -float 800
defaults write com.knollsoft.Rectangle specifiedWidth -float 1330defaults write com.knollsoft.Rectangle specifiedHeight -float 950
defaults write com.knollsoft.Rectangle specifiedWidth -float 1550defaults write com.knollsoft.Rectangle specifiedHeight -float 800
defaults write com.knollsoft.Rectangle specifiedWidth -float 1152Then quit rectangular and restart.
2021
Jul 05
GPU 数感 | 通感 | 常识
架构
- GA100 Ampere Specs
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs/GPU
Ref: 2021-07-05-nvidia-ampere-architecture-whitepaper.pdf
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs/GPU
FLOPS
每秒浮点运算次数 (FLOPS)
- gigaFLOPS GFLOPS 10^9
- teraFLOPS TFLOPS 10^12
- NVIDIA GeForce RTX 2080 Ti :13.45 TFLOPS
Memory
1 Million 的 float 是 4 MB 1 Billion 的 float 是 4 GB
GPU compute capability vs architecture list:
| Compute Capability |
Architecture Name |
|---|---|
| 8 | Ampere |
| 7.5 | Turing |
| 7 | Volta |
| 6 | Pascal |
| 5 | Maxwell |
| 3 | Kepler |
| 2 | Fermi |
| 1 | Tesla |
Ref:
2021
Jul 02
安装 Windows
- NVME M.2 安装 Windows 的坑: https://www.dell.com/support/kbdoc/zh-cn/000132465/windows-10-安装-带-nvme-ssd-和-sata-驱动器
- linux 制做 U 盘时需要手动 sync
cp src dest sync # manual sync to assure write is done watch -n 1 -d 'cat /proc/meminfo | grep Dirty' # check sync progress
2021
Jul 01
IO 性能测试
dd if=/dev/zero of=~/test1.img bs=1G count=1 oflag=dsync
dd if=/dev/zero of=~/test2.img bs=512 count=1000 oflag=dsync2021
Jun 30
Jupyter multiple environment
conda activate base
conda install -c conda-forge nb_conda
jupyter notebook2021
Jun 26
Helloworld! This account will be used to share useful wikis, and will be public accessable.
2021
Apr 21
Disable lghub
- kill background update process
- ps -A | grep hub
- kill the process of /Applications/lghub.app/Contents/Frameworks/lghub_updater.app/Contents/MacOS/lghub_updater
- disable auto start when restart computer
- change
RunAtLoadto be false for /Library/LaunchAgents/com.logi.ghub.plist - change
RunAtLoadto be false,KeepAliveto be false,Disabledto be true for /Library/LaunchDaemons/com.logi.ghub.updater.plist
- change
2021
Mar 18
CUDA Memory Transcation
读global mem,从L1走的话(默认L1),一个transaction是32个float。 但是,可以指定从 L2走,L2走的话,一个transaction可以是1,2,4个segments,每个segments是8个float。 所以 如果memory access 不是 coalessing的话,L2走 利用率更高。 或者 如果 一个warp 访问的是同一个元素,L2也快。 Ref:
- 2013 GTC Programming-Guidelines-GPU-Architecture - backup
- 2012 GTC GPU-Performance-Analysis - backup
- 2010 GTC Better Performance at Lower Occupancy - backup
- 2018 GTC volta architecture and performance optimization
- 2011 register_spilling
2021
Feb 13
蛋白质
- 蛋白质摄入过多的危害有哪些? - 知乎
- 为什么会有红肉白肉之分?他们含有什么让他们颜色不同? - 知乎
- 图 红肉和白肉的区别
- 每一百克肉类中的脂肪含量
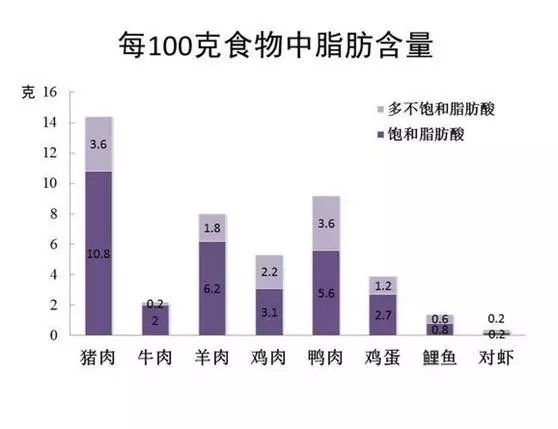
- 红肉和白肉的区别
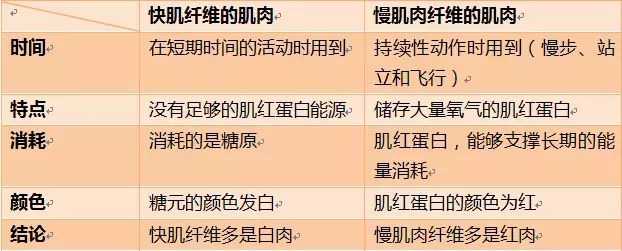{kind=link}
| 快肌纤维的肌肉 | 慢肌肉纤维的肌肉 | |
|---|---|---|
| 时间 | 在短期时间的活动时用到 | 持续性动作时用到(慢步、站立和飞行) |
| 特点 | 没有足够的肌红蛋白能源 | 储存大量氧气的肌红蛋白 |
| 消耗 | 消耗的是糖原 | 肌红蛋白,能够支撑长期的能量消耗 |
| 颜色 | 糖元的颜色发白 | 肌红蛋白的颜色为红 |
| 结论 | 快肌纤维多是白肉 | 慢肌肉纤维多是红肉 |
2021
Feb 11
Scan (cumsum)
Blockwise communication
// wait for the previous block finish the partial sum
while(Atomicadd(sum[sbid], 0) == 0) {;}
// do the job
do
// give signal to the next block
Atomicadd(sum[sbid+1], 1)Dynamic blockIdx assignment
上面的问题希望让 block 顺序执行,如果 scheduler backward 分配 block,后面的 block 在运行,并且等待着previous block 的结果,但是 SM 不足以分配资源给 previous block,很可能会产生 deadlock。 blockIdx.x 本是 block 的 id,不用这个。因为这个id无法保证sceduler是顺序分配的。 解决办法是在 global memory 定义一个 blockidcounter,每个block执行的时候,thread0 对counter atomicadd加一。 这样blockidx就是顺序执行的了。
2021
Jan 29
Cgroup V2
Nvidia-docker
Edit /etc/nvidia-container-runtime/config.toml and change #no-cgroups=false to no-cgroups=true.
After a restart of the docker.service sudo systemctl restart docker everything will work as usual.
System
Kernel/KernelBootParameters - Ubuntu Wiki
sudo vim /etc/default/grub
# GRUB_CMDLINE_LINUX_DEFAULT="quiet splash systemd.unified_cgroup_hierarchy=1"
sudo update-grubDocker
Plex needs
sudo mkdir /sys/fs/cgroup/systemd
sudo mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemdhttps://github.com/docker/for-linux/issues/219#issuecomment-375160449
restart will have issue
fix by add into /etc/init.d/my-cgroup-systemd
-rwxr-xr-x 1 root root 96 Mar 5 22:40 my-cgroup-systemdmkdir /sys/fs/cgroup/systemd
mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemdthen edit /etc/rc.local add the script file path
2021
Jan 20
Compile Pytorch with cuda/10.0 on hipergator
srun -p gpu --ntasks=1 --cpus-per-task=10 --gpus=geforce:1 --time=02:00:00 --mem=50gb --pty -u bash -iprepare environment
conda activate base
conda install cudatoolkit=10.0
conda install -c pytorch magma-cuda100 # also install magma in base
conda create -n cuaev python=3.7
conda activate cuaev
conda install cudatoolkit=10.0 # yeah do it again
conda install -c pytorch magma-cuda100
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
module load cuda/10.0.130
module load gcc/7.3.0
export CUDA_HOME=/apps/compilers/cuda/10.0.130Install pytorch (from pytorch/pytorch )
conda install numpy ninja pyyaml mkl mkl-include setuptools cmake cffi typing_extensions future six requests dataclasses
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py install # will take about half a hourCheck pytorch
python -c 'from torch.utils.collect_env import get_pretty_env_info; print(get_pretty_env_info())'2020
2020
Dec 22
2020
Nov 17
2020
Nov 13
Python String 对齐
str.ljust()
str.rjust()
str.center()header_lens = {'function': 10, 'time': 10, 'count': 10}
timers = {'run': 10, 'forward': 8, 'backward': 4}
counts = {'run': 1, 'forward': 1, 'backward': 1}
for h, l in header_lens.items():
print(h.rjust(l), end ="")
print()
for k in timers:
print(k.rjust(header_lens['function']), end ="")
print(str(timers[k]).rjust(header_lens['time']), end ="")
print(str(counts[k]).rjust(header_lens['count']), end ="")
print()output
function time count
run 10 1
forward 8 1
backward 4 12020
Oct 23
Docker 绕过 UFW 规则,导致重大安全隐患
Docker publish 的所有端口会绕过 UFW 设定的规则,导致无意公开的内部服务可以被公网访问。 尤其是弱智 mongodb 默认不需要 authentication 就能操作所有 database,因此在不知情的情况下,mongo 裸奔,被黑客攻击,删除数据勒索。
相关case:
防护措施
chaifeng/ufw-docker: To fix the Docker and UFW security flaw without disabling iptables
在 /etc/ufw/after.rules 最后添加 iptables 代码:
参照 WeiNote - Docker UFW 防护措施
重启
sudo systemctl restart ufw测试端口 port
nmap -p 27017 server.com
nmap server.com- open / closed: 说明端口开启了
- filterd: 说明被防火墙屏蔽
telnet server.com 27017Mongo 安全
mongoDB 数据莫名其妙的没了_技术熊的博客小窝-CSDN博客 config 文件 设置 auth=true,就不会裸奔了,必须要有密码才能访问,否则不需要任何authentication就能操作任何数据库!
port = 27017
bind_ip = 127.0.0.1
auth = trueDocker ports
Use the following format will be more secure
ports:
- "127.0.0.1:8001:8001"- Compose file version 3 reference | Docker Documentation
- Docker EXPOSE a port only to Host - Stack Overflow
查看 docker 更改的 iptables
sudo iptables -L DOCKER
Chain DOCKER (2 references)
target prot opt source destination
ACCEPT tcp -- anywhere 172.18.0.2 tcp dpt:27017to get more information about a container
docker inspect $ID2020
Sep 23
Data Representation
Float32

- 6张图搞懂float浮点型底层存储原理 - 武沛齐 - 博客园
- IEEE754 浮点数的表示方法_Dablelv的博客专栏-CSDN博客_ieee754
- IEEE 754 - 维基百科,自由的百科全书
Tensorfloat32
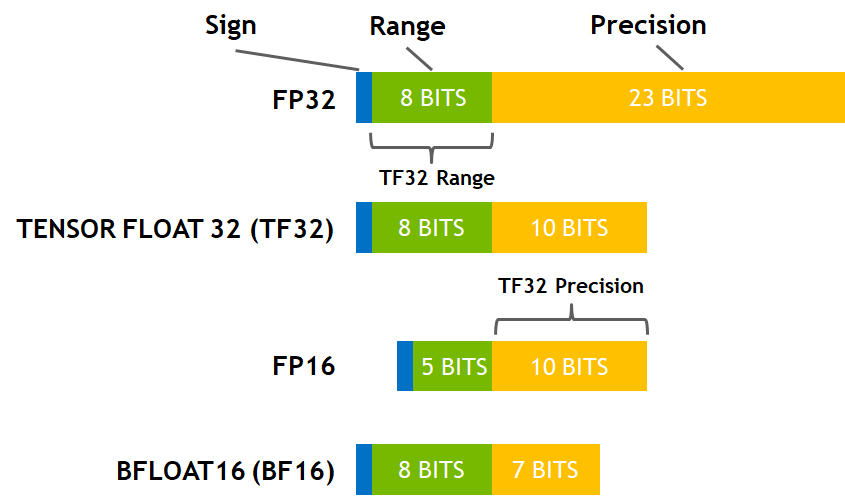
Ref: Accelerating AI Training with NVIDIA TF32 Tensor Cores | NVIDIA Developer Blog
2020
Jul 18
Python参数传递
- Python参数传递,既不是传值也不是传引用 - simpleapples
- python - How do I pass a variable by reference? - Stack Overflow
可变对象和不可变对象
a = [1, 2, 3]
def mutate(a):
a += [4]
print(a) # [1, 2, 3]
mutate(a)
print(a) # [1, 2, 3, 4]
b = 1
def mutate(b):
b += 1
print(b) # 1
mutate(b)
print(b) # 1函数也是对象,默认参数只初始化一次
def test(b=[]):
b += [1]
print(b)
test() # [1]
test() # [1, 1]
test() # [1, 1, 1]def test(b=None):
b = b or []
b += [1]
print(b)
test() # [1]
test() # [1]
test() # [1]函数默认值在定义时初始化,而不是执行时
i = 1
def test(a=i):
print(a)
i = 2
test() # 12020
Jul 17
Multiprocessing
Contexts and start methods
- fork: child process typically can access the dataset and Python argument functions directly through the cloned address space.
- spawn: pickle all parent data, slower
Reference:
- multiprocessing — Process-based parallelism — Python 3.8.4 documentation
- Single- and Multi-process Data Loading
Wrap a function to an object with several input
import functools
a = functools.partial(f, n=20)Reference: Python multiprocessing a function with several inputs - Stack Overflow
Example
processes = []
torch.multiprocessing.set_start_method('fork')
for rank in range(self.world_size):
p = torch.multiprocessing.Process(target=worker, args=(rank, self.config))
p.start()
processes.append(p)
for p in processes:
p.join()2020
Jul 06
ffmpeg
mp4 -> mp3
mkdir outputs
for f in *.mp4; do ffmpeg -i "$f" -c:a libmp3lame "outputs/${f%.mp4}.mp3"; donecut 视频
ffmpeg -ss 00:02:46 -i 勇气.mov -to 00:06:47 -c copy 勇气o.mov
ffmpeg -ss 00:00:00 -i 21.mp4 -to 00:00:10 -c copy o21.mp4cut mp3
ffmpeg -ss 00:00:00 -to 00:10:00 -i inputfile.mp3 -c copy outputfile.mp3调高音量
ffmpeg -i input.mp3 -af volume=23dB output.mp3使输出文件能够快速加载并播放(通过将index等数据放在mp4文件起始位置)
ffmpeg -i input.mp4 -movflags +faststart output.mp42020
Jun 02
铲屎官 笔记
猫癣
环境消毒
- 1:10稀释的含氯消毒产品
2020-06-17
- 猫癣,有人用过石硫合剂吗?管用吗?- 豆瓣
- 猫癣:想说再见不容易_好主人
- 猫癣老不好?看看你是不是也做错了这5件事! - 知乎
- 治疗猫藓的详细经历和个人心得~ - 知乎
- 猫癣其实很好治—我们在国外怎么诊断和防治猫癣 - 小红书
- 花少钱养好猫篇二:经济方便的根治猫癣 - 知乎
- 这是一篇很全的很省钱的抗猫癣笔记哦~~ - 知乎
- 这是一篇很全的很省钱的抗猫癣笔记哦~ - 小红书
2020-06-02
驱虫
猫砂
2020
Mar 14
Python tips and tricks
List Comprehensions
# [ expression for item in list if conditional ]
def square(x):
return x**2
a = [square(i) for i in range(10) if (i % 2 == 0)]
# [0, 4, 16, 36, 64]if else
>>> a = [10, -1, 1, -10, None, 0, None, 0]
>>> [x if x > 0 else -x for x in a if x]
[10, 1, 1, 10]dataclass, Python 3.7 中 dataclass
from dataclasses import dataclass
@dataclass
class Card:
rank: str
suit: str
card = Card("Q", "hearts")
print(card == card)
# TrueSlicing a list
a[start:stop:step] , default is a[0:-1:1]
"abcdefgh"[::2]
# 'aceg'
"abcd"[::-1]
# 'dcba'map
def upper(s):
return s.upper()
mylist = list(map(upper, ['sentence', 'fragment']))
# ['SENTENCE', 'FRAGMENT']Ternary Operator For Conditional Assignment
x = "Success!" if (y == 2) else "Failed!"Integer division
Python 3
5 / 2 = 2.5
5 // 2 = 2Avoid using np.append for big array in for loop
In [1]: import numpy as np
In [2]: %%timeit
...: a = np.array(1)
...: for i in range(5000):
...: a = np.append(a, 1)
...:
31.8 ms ± 615 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [3]: %%timeit
...: a = [1]
...: for i in range(5000):
...: a.append(1)
...:
380 µs ± 9.29 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)Reference:
30 Python Best Practices, Tips, And Tricks - Towards Data Science
2020
Mar 06
编译器
LLVM / Clang / GCC
- Clang 比 GCC 好在哪里? - 知乎
- GCC,LLVM,Clang编译器对比 - qoakzmxncb - 博客园
- LLVM每日谈之二 LLVM IR - 知乎
- 传统的静态编译器分为三个阶段:前端、优化和后端

- LLVM的三阶段设计
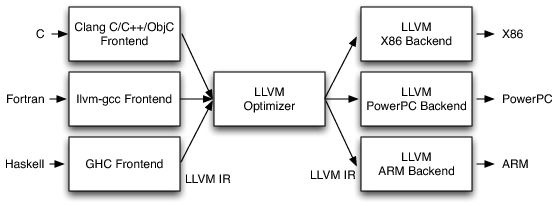
MLIR - Chris Lattner
MLIR (Multi-Level Intermediate Representation)
XLA - TF
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes. Most internal benchmarks run ~1.15x faster after XLA is enabled.
2020
Feb 03
Python notes
copy.copy() and copy.deepcopy()
>>> a = [1, 2, [3]]
>>> c = copy.deepcopy(a)
>>> b = copy.copy(a)
>>> a[-1][0] = 4
>>> a
[1, 2, [4]]
>>> b
[1, 2, [4]]
>>> c
[1, 2, [3]]is and ==
a = 1
b = 1
a == b # True | Value
a is b # False | ObjectSort
intervals = [[1, 2], [2, 3], [5, 8], [0, 1]]
intervals.sort(key=lambda x: x[0])from functools import cmp_to_key
def cmp_xy(x, y):
spe_dict = {'C':1, 'H':0, 'N':1, 'O':2}
x = spe_dict[x]
y = spe_dict[y]
if x > y:
return 1
elif x < y:
return -1
else:
return 0
a = ['C', 'H', 'N', 'O']
a.sort(key=cmp_to_key(cmp_xy))
print(a) # ['H', 'C', 'N', 'O']Ref: Reference
a = ['C', 'H', 'N', 'O']
spe_dict = {'C':1, 'H':0, 'N':1, 'O':2}
a.sort(key=lambda x: spe_dict[x])
print(a) # ['H', 'C', 'N', 'O']dict.values()
dict.keys()
dict.items()
max(dict, key=dict.get)
max(dict.keys(), key=lambda k: dict[k])2019
2019
Dec 08
Python Internal
Book Inside The Python Virtual Machine pdf | Read online Python源码剖析 pdf
CPython的Global Interprate Lock(GIL): Preventing multiple threads from executing Python bytecodes at once.
大家听说过对 CPython的GIL的抱怨不?经常听到对不对? 有多少一般 Python用户知道吐槽GIL其实真的在吐槽的就是 CPython的引用计数及C API实现? -- 知乎
-
Done is better than perfect
2019
Nov 20
Use python in bash script
Simple case:
for i in {0..5}
do
file=$(python -c "a='wavefunction{:02d}'.format($i); print(a)")
echo $file
sleep 0.5
done
#wavefunction00
#...
#wavefunction05python -c "print('some')"
some #outputa=$(python -c "a='I am {}'.format('richard'); print(a)")
echo $a
I am richard #outputa=$(python -c "print('some')" 2>&1) # 2>&1的意思是python的stderr输出重定向到stdout
echo $a
some #outputfor i in {0..29}
do
echo $i
python -c "import os; os.remove('input'); a = 'blabla'; print(a); file=open('input', 'w+'); file.write(a); file.close()"
cpptraj -p ../template.pdb -i input
done2019
Oct 04
Slurm
Enforce memory limit for jobs
related settings: /etc/slurm-llnl/slurm.conf
TaskPlugin = task/affinity,task/cgroup
MaxMemPerNode=100000
DefMemPerNode=100000
DefMemPerCPU=5000
SelectTypeParameters=CR_CPU_Memory/etc/slurm-llnl/cgroup.conf
ConstrainRAMSpace=yesThe default mem-per-cpu is 5gb, you can specify more using #SBATCH --mem-per-cpu=10gb for example in your script.
If the job exceed the requested mem, it will get killed by slurm to avoid OOM system error.
Ref: hpc - Cannot enforce memory limits in SLURM - Stack Overflow
Update Slurm after Replace GPU
If chang gpu on mordor or isengard, both of them needs to be updated
sudo vim /etc/slurm-llnl/slurm.conf
sudo vim /etc/slurm-llnl/gres.confThen restart
sudo /etc/init.d/slurmd restart
sudo /etc/init.d/slurmctld restart2019
Sep 09
VSCode Shortcuts

Code > Preferences > Keyboard Shortcuts > keybindings.json (see image above)
[
{
"key": "ctrl+shift+tab",
"command": "workbench.action.previousEditor"
},
{
"key": "ctrl+tab",
"command": "workbench.action.nextEditor"
},
{
"key": "ctrl+,",
"command": "workbench.action.decreaseViewSize"
},
{
"key": "ctrl+.",
"command": "workbench.action.increaseViewSize"
}
]For github1s
// Place your key bindings in this file to override the defaults
[
{
"key": "alt+shift+tab",
"command": "workbench.action.previousEditor"
},
{
"key": "alt+tab",
"command": "workbench.action.nextEditor"
},
{
"key": "ctrl+,",
"command": "workbench.action.decreaseViewSize"
},
{
"key": "ctrl+.",
"command": "workbench.action.increaseViewSize"
},
{
"key": "ctrl+w",
"command": "workbench.action.closeActiveEditor"
},
{
"key": "cmd+w",
"command": "-workbench.action.closeActiveEditor"
}
]2019
Aug 14
Python String format
"{:,}".format(123456789)
'123,456,789''CPU {: 4d}%'.format(100)
'CPU {: 4d}%'.format(10)
'CPU {: 4d}%'.format(0)
CPU 100%
CPU 10%
CPU 0%'CPU {:04d}%'.format(100)
'CPU {:04d}%'.format(10)
'CPU {:04d}%'.format(0)
CPU 0100%
CPU 0010%
CPU 0000%If there is {} in string, change it to {{}}
"dict = {{'a': {}}}".format(1)
"dict = {'a': 1}"Ref: str.format()
2019
Jun 30
Wireguard
Install
Set Up WireGuard VPN on Ubuntu | Linode
Server
Enable ip forward
sudo vim /etc/sysctl.conf
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
sudo sysctl -pIPv6
tcpdump
sudo tcpdump -i wg0 port 22$ sudo tcpdump -i wg0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wg0, link-type RAW (Raw IP), capture size 262144 bytes
12:05:06.856663 IP 111.11.1.2 > 111.11.1.3: ICMP echo request, id 28433, seq 0, length 64
12:05:06.856721 IP 111.11.1.2 > 111.11.1.3: ICMP echo request, id 28433, seq 0, length 64
12:05:06.876567 IP 111.11.1.3 > 111.11.1.2: ICMP echo reply, id 28433, seq 0, length 64
12:05:06.876592 IP 111.11.1.3 > 111.11.1.2: ICMP echo reply, id 28433, seq 0, length 64
12:05:07.859800 IP 111.11.1.2 > 111.11.1.3: ICMP echo request, id 28433, seq 1, length 64
12:05:07.859827 IP 111.11.1.2 > 111.11.1.3: ICMP echo request, id 28433, seq 1, length 64
12:05:07.879684 IP 111.11.1.3 > 111.11.1.2: ICMP echo reply, id 28433, seq 1, length 64
12:05:07.879707 IP 111.11.1.3 > 111.11.1.2: ICMP echo reply, id 28433, seq 1, length 64ping
richard@mbpr > ping 111.11.1.3
PING 111.11.1.3 (111.11.1.3): 56 data bytes
64 bytes from 111.11.1.3: icmp_seq=0 ttl=63 time=32.214 ms
64 bytes from 111.11.1.3: icmp_seq=1 ttl=63 time=32.074 ms
^C
--- 111.11.1.3 ping statistics ---
2 packets transmitted, 2 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 32.074/32.144/32.214/0.070 msRef:
Mac wg-quick
wg-quick: Version mismatch: bash 3 detected, when bash 4+ required
brew install bash
export PATH=/usr/local/bin:$PATHMac run at login / startup
/Library/LaunchDaemons/com.startup.script.plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.wireguard.startup.plist</string>
<key>Disabled</key>
<false/>
<key>RunAtLoad</key>
<true/>
<key>KeepAlive</key>
<false/>
<key>LaunchOnlyOnce</key>
<true/>
<key>ProgramArguments</key>
<array>
<string>/bin/bash</string>
<string>/Users/richard/bin/run-wg-on-start</string>
</array>
<key>StandardOutPath</key>
<string>/tmp/wireguard.start.log</string>
<key>StandardErrorPath</key>
<string>/tmp/wireguard.start.err</string>
</dict>
</plist>~/bin/run-wg-on-start
#! /usr/local/bin/bash
export PATH=/usr/local/bin:$PATH
/usr/local/bin/wg-quick up /path/to/wireguard/wg0.conf
sleep 2147483647 # 24855 days
echo quitting wireguard after 2147483647sload service
sudo launchctl load /Library/LaunchDaemons/com.startup.script.plistRef:
- freedev/macosx-script-boot-shutdown: This project is useful to execute a shell script during Mac OS X boot or shutdown.
- terminal - Run script as root at startup - macOS 10.12 Sierra - Ask Different
切换server
linux
sudo wg-quick down /path/to/wireguard/wg0.conf; sudo wg-quick up /path/to/wireguard/wg0.conf;mac
sudo wg-quick down /path/to/wireguard/wg0.conf; sudo wg-quick up /path/to/wireguard/wg0.conf;如果旧的 server 还在运行,因为旧的 server 还在 不断的和 client (e.g. mac) 握手通讯,client 的 wg 会以为 server 还是旧的 server,因此 sudo wg 会显示新 server ip 之后,又切换回旧 server 的 ip 。
正确做法是关闭旧 server 的 wg 服务,从而顺利切换新的 server。
server
sudo systemctl enable wg-quick@wg0.serviceadd a new peer
sudo systemctl restart wg-quick@wg0